使用influxdb替换原clickhouse的设备历史轨迹点位数据备份
参考: https://docs.influxdb.org.cn/influxdb3/core/ 中文文档,不太全
https://docs.influxdata.com/influxdb3/core 英文文档,新且全
安装
- 直接官方文档二进制安装(由于机器有点老,没搞docker,跟着提示安装就好),我安装完版本为 3.2.1
curl -O https://influxdb.org.cn/d/install_influxdb3.sh && sh install_influxdb3.sh
- why 3.0:
- 内部支持s3,必要的话可以把数据直接传到s3兼容的腾讯/阿里/MiniIO 存储中
- Apaceh Parquet存储,必要时可以使用工具直接装载文件,比如 DuckDB
- 开源版本限制:
- 最多5个数据库
- 全局最多2000个表
- 每个表最多500个列(包含tag/time,ps:这是一个性能优化限制)
- 以下摘自官方文档
InfluxDB 3 Core 是 InfluxDB 3 开源版本。Core 的功能亮点包括 支持对象存储的无盘架构(或无依赖的本地磁盘) 快速查询响应时间(最后值查询低于 10 毫秒,或不同元数据查询低于 30 毫秒) 用于插件和触发器的嵌入式 Python VM parquet 文件持久化 与 InfluxDB 1.x 和 2.x 写入 API 兼容
- 添加完后会自动启动,建议加入systemd启动项,手动启动命令如下
influxdb3 serve --node-id=node0 --http-bind=0.0.0.0:8181 --object-store=file --data-dir /influxdb/data # 一些启动参数 --snapshotted-wal-files-to-keep=100 #保留100个wal --wal-snapshot-size=100 #积压100个wal后压缩器开始工作,调低可降低内存占用 --wal-flush-interval=2s #最大写入延迟,默认1s,backup场景可以 --gen1-duration=10m #多长时间生成一个purquet文件 --parquet-mem-cache-size=xxx # 缓存大小M为单位,默认1000 --query-file-limit #查询时调用的最大文件个数,默认432,可访问72小时数据,建议调协更低的值 --datafusion-max-parquet-fanout #最大排序文件数 - 安装后添加管理token,注官方推荐是https但我这里https好像连不上,应该需要配置
influxdb3 create token --admin --host http://127.0.0.1:8181
返回如下(这个token很重要,要记下来以后用)
New token created successfully!
Token: apiv3_19Fu30mrVCITljdyxd3WVS9NJZWXoFDi0v3NSv4QrUZj9z4yxJIY6S1DVCgwDhBAqUrQQsQ69vz7XvyH5DetQw_z
HTTP Requests Header: Authorization: Bearer apiv3_19Fu30mrVCITljdyxd3WVS9NJZWXoFDi0v3NSv4QrUZj9z4yxJIY6S1DVCgwDhBAqUrQQsQ69vz7XvyH5DetQw_z
- 可以考虑装个UI,在另外一台有docker的机器上装了influxdata/influxdb3-ui这个镜像,启动是建议调一下端口,80/443被占用的概率比较大,我这里使用了8182
- 装好http://ip:8182进来添加服务器,输入服务器名/地址:端口/token(就上面生成的那串,即可连接服务器)
- 刚打开还有一个
废话引导界面
- 刚打开还有一个
- 主要功能就一个Query Data,可使用SQL查询,旁边还有一个自然语言查询
- 查询界面仅支持show,select开头的查询语句
- 启动时加入 --mode=admin,可以管理库和token,同时多了一个写入数据界面,可以导入csv和json
- 自然语言查询需要配OpenAI Key,没有可以配baseUrl的地方
- 还有一个Grafana集成可用于快速创建面板啥的
- 装好http://ip:8182进来添加服务器,输入服务器名/地址:端口/token(就上面生成的那串,即可连接服务器)
简单查询
- 创建库表
# 注意 --token 要写在最后 influxdb3 create database test --token ***** # -d 表示db influxdb3 create table test -d test --token *** # tags可以在创建表时带上,也可以在写入数据时自动生成(fields同样) influxdb3 create table test2 -d test --tags test1,test2 --token *** - 删除表,默认为软删除,硬删除可以添加 (--hard-delete now)参数
influxdb3 delete table test -d test --token # 也可以用库表API来删除表 硬删除时添加 &hard_delete_at=<RFC3339时间> curl -X DELETE "http://localhost:8181/api/v3/configure/table?db=<DATABASE_NAME>&table=<TABLE_NAME>" \ --header "Authorization: Bearer <AUTH_TOKEN>"- 软删除逻辑是先给原表改名,然后等job清理
- 写入数据
- 仅支持行协议模式写入,格式如下(官方截图)
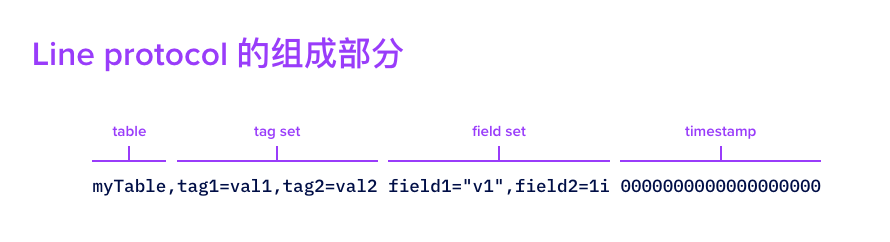
- 和Prometheus的区别主要在于Prometheus没有field集,只有一个value值
- 如果时间戳不写,将使用服务器当前时间
- 标签 key,value 均为字符串
- 时间戳最大精度为纳表
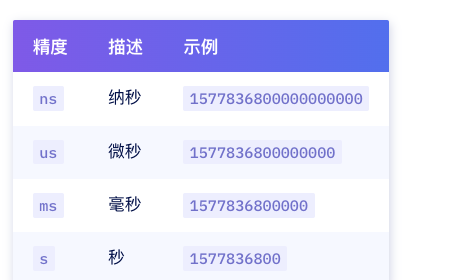
- 疑问:秒级时间戳到2286年升位了杂算
- 字段值可选如下
- 浮点数,直接字面量或科学计数法,如: 1 , 1.0 , -1.28e+2
- 注: 直接写数字不加后缀为浮点数
- 有符号整型,需加后缀 i,如: 40i
- 无符号整型,需加后缀 u,如: 40u
- 字符串,带双引号的字面量,如: "hello world"
- 布尔值, i不带引号的true/false, 如: t,T,true,True,TRUE,f,F,False,FALSE
- 浮点数,直接字面量或科学计数法,如: 1 , 1.0 , -1.28e+2
- 写入单行数据(注:写入第一条数据数据时如果库表不存在,会自动创建)
influxdb3 write -d test --token *** 'test,test1=test,test2=test value=0' # 注: cli情况下lp必须写在最后,并且用引号包裹
- 仅支持行协议模式写入,格式如下(官方截图)
- 查询数据
- 3.0 可以直接用sql查询,并且支持窗口函数和with语句
- 注意时区问题,infulxdb查询输出带T的UTC时间,查询同样需要使用带TZ的RFC3339时间格式
- 如查询 6月6日0点到1点的数据需要这么写
SELECT *, tz(time, 'Asia/Shanghai' ) as tz_time from test3 WHERE time >= '2025-06-06T00:00:00+08:00' AND time < '2025-06-06T01:00:00+08:00' ORDER BY time - 同时也支持自家的类sql语言InfluxQL
数据导入
统计了一下,当前ck里第个月备份数据最大有6.5亿条,平均月有4亿条,至少需要备份12个月近50亿数据
- 方案
- DataX
- 阿里开源java的数据迁移工具,之前更换数据库实例时用过,没阿里在线那个好用
- 可以参考这篇: https://developer.aliyun.com/article/722043
- 上面连接中提供了influxdb插件,但从文件时间上来看,最后更新时间是2000年,只支持1.x版本的inluxdb,
- 导出数据,转换为行协议格式,再导入
- 由于原ck机器配置相对较低,导出10天数据都需要很久时间
- 自建脚本查出后导入
- 小试一下go,CodeBuddy vibe coding 2小时完成
- go的交叉编译很方便
- 按天迁移支持设置一批次数量,及并发数
- 挂服务器上迁移ing
- 我机器配置低(内存8G,同时在跑ck)并发只给了10,一天数据迁移20分钟左右,预计需要2天
- 期间有触发系统oom kill的情况,已通过调整--wal-snapshot-size=100 来降低压缩时内存占用,调整后10个并发一批次6000写入占用内存1.3G左右,cpu占用35%以内
- 内存低的机器同时需要注意查询时内在占用
- 小试一下go,CodeBuddy vibe coding 2小时完成
- DataX
业务使用
- 重新写了一个go版本的mysql到influxdb的迁移工具
- 这次vibe coding失效了,怎么让他改,都一片乱,最终大部分代码是自己写的,go写起来还是蛮爽的
- ps: Windsurf的tab 很好用,很自然,
高可用方案思考
influxDB官方企业版/集群版 有高可用支持,但开源版本没有,v1/v2 版本有社区方案,v3比较新目前没找到社区方案,可以尝试以下方案
- nginx mirror写流量重放/upstream均衡
- 内置python触发器流量转发到backup服务器
- https://docs.influxdb.org.cn/influxdb3/core/plugins/
- 建议一主两备,主写流量转发备1,备2,同时nginx做backup均衡
- FileSync 整个data目录(backUp)
- v1/v2 influxdb-relay/influx-proxy
- 由于v3写入api接口兼容v1/v2,理论上可以用v1/v2的代理方案
- 可用性未知,待测试