时间线
- 21:40 微信群收到job异常报警
- 21:50 连续多个不同JOB开始异常
- 同时收到网关健康度下降报警
- 22:10 进入排查
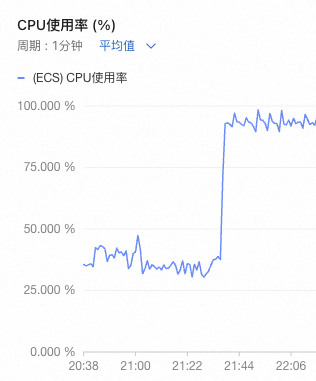
- 发现web2服务器cpu超过90%以上,且很多job调度请求timeout
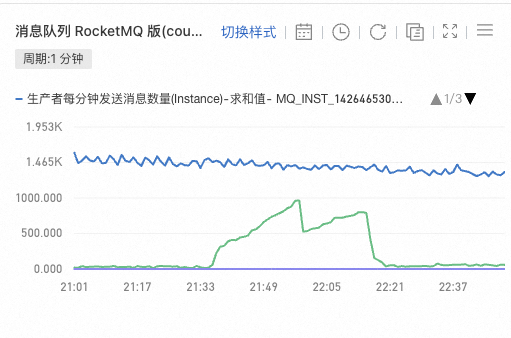
- 发现消息队列积压严重,但消息总量并没有比以往有明显的上
- 同时发现内存占用并不大,并没有超过40%
- 由于web网关配置健康检测,出问题后web请求路由到了其他服务器,对用户服务影响较小
- 22:15 调整web3服务器,开启备用消息队列消费器
- 22:18 消息队列积压消除
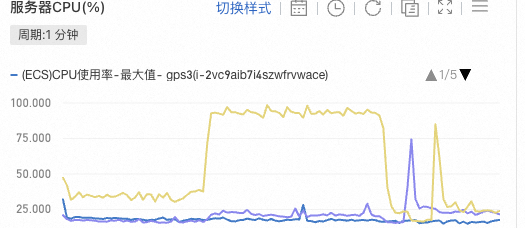
- 22:20 重启web2服务器
- 22:30 web2服务器执行一个job时cpu又到了85%以上
- 22:30 查看第一个job报错日志发现 Caused by: java.lang.OutOfMemoryError: Metaspace
- 22:30 检查web2 启动参数发现 -XX:MaxMetaspaceSize=156m(疑似新服务上线调整参数时将256写成了156)
- 根据经验和以往监控,此项目启动后需要 Metaspace 140M左右
- 由于定时任务需要处理10万级数据,Metaspace会急剧上升导致不断触发FULL GC
- 核心原因是在处理列表数据时大量使用了spring的BeanUtils.copyProperties反射来进行DTO转换导致
- 最终导致cpu一直居高不下,甚至机器拒绝响应
- 22:35 调整 -XX:MaxMetaspaceSize=512m 后重启服务器,恢复正常
弄完已经23:40,睡觉
后续
- 找到Metaspace在执行job是增大核心原因
- 经检查,核心原因是在处理列表数据时大量使用了spring的BeanUtils.copyProperties反射来进行DTO转换导致
- BeanUtils.copyProperties 在copy时大量用到反射,生成了大量的代理类
- 排查过程参考:https://javakk.com/160.html
- DTO转换类util改为使用BeanCopier来减少反射
- BeanCopier原理是ASM直接修改字节码
- 已完成
- 参考:https://www.cnblogs.com/HeiDaotu/p/15946140.html
- 参考:https://xiaoyue26.github.io/2020/05/05/2020-05/BeanCopier测评报告/
- 由于之前代码很多转换list是steam流一个一个转换的,为避免频繁create使用了懒汉map缓存BeanCopier的方式
- 检查线上服务,MaxMetaspaceSize至少要大于192m
- 建议小公司机器不要低于2核4G,稍大一点的项目不要低于2核8G