之前日志方案是基于clickhouse的,但是由于机器配置低(2C2G),出现过几次cpu跑满机器挂掉的情况
偶尔看到OpenObserve(简称o2)发现不错,自带像Kibana的日志查询框架
更新:建议用新版本,新版本首页好看了一点
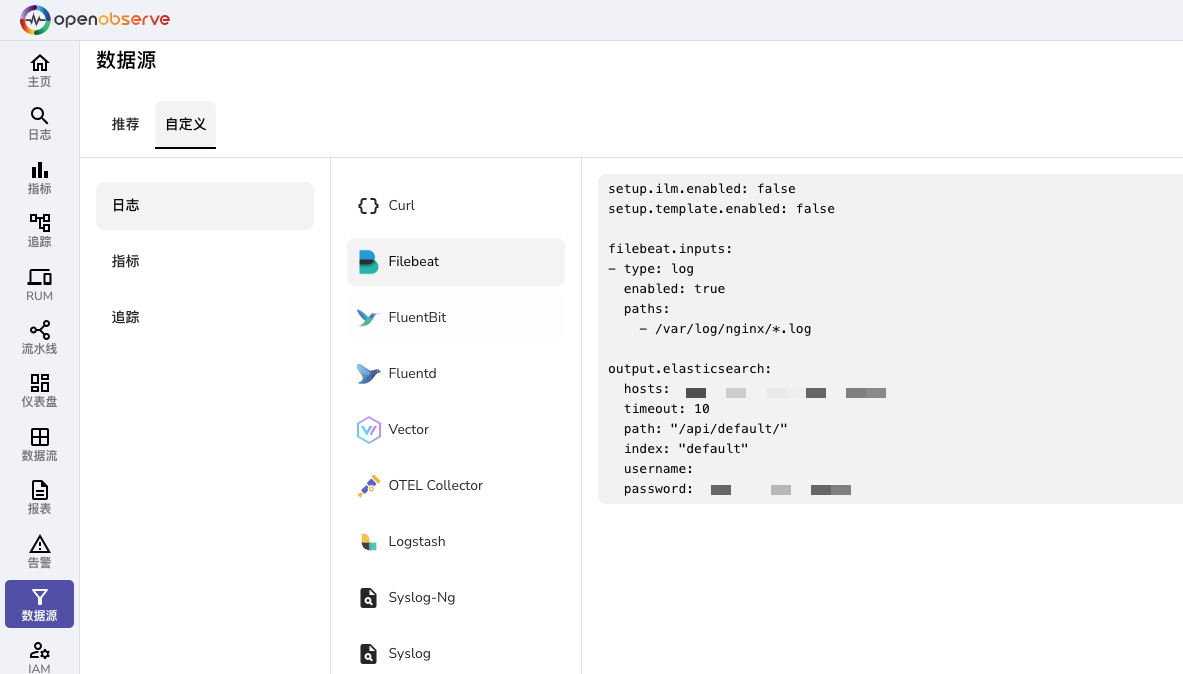
服务端安装
- 官网文档安装即可
- https://openobserve.ai/docs/quickstart/#__tabbed_1_2
- 由于机器配置低,没有使用docker方案,使用二进制
- 如果是云服务器的话,建议cpu/mem为1/2,即最低2核4g, 磁盘IOPS不低于3000
curl -L https://raw.githubusercontent.com/openobserve/openobserve/main/download.sh | sh ZO_ROOT_USER_EMAIL="root@example.com" ZO_ROOT_USER_PASSWORD="Complexpass#123" ./openobserve- 如果速度慢,可以自行去github下载release
- https://github.com/openobserve/openobserve/releases
- 解压后只有一个openobserve可执行文件
- 如果机器支持SIMD指令,可以下载带SIMD的版本,可加快索引计算速度
- 默认端口 5080,通常不需要改
- 可以根据官网调整一此参数,写一个sh运行
- https://openobserve.ai/docs/environment-variables/
- 经测试,如下配置后内存占用比之前少了10%,减少当机风险
- 可以配置存储到s3或MiniIo,兼容国内oss/bos/cos/us3
- 个人配置如下
export ZO_ROOT_USER_EMAIL="root@example.com" export ZO_ROOT_USER_PASSWORD="Complexpass#123" # 日志level,性能提升明显 export RUST_LOG=error # 每个cpu一个WAL export ZO_FEATURE_PER_THREAD_LOCK=true # 内存缓存大小 export ZO_MAX_FILE_SIZE_IN_MEMORY=64 # 压缩配置 export ZO_COMPACT_INTERVAL=30 export ZO_COMPACT_MAX_FILE_SIZE=512 export ZO_COMPACT_DATA_RETENTION_DAYS=30 export ZO_COMPACT_SYNC_TO_DB_INTERVAL=300 export ZO_COMPACT_DELETE_FILES_DELAY_HOURS=12 # 快速压缩,吃内存 export ZO_COMPACT_FAST_MODE=false # 是否上报诊断信息 export ZO_TELEMETRY=false # 关闭MMDB下载,好像没啥用,下载的文件还很大(60M) export ZO_MMDB_DISABLE_DOWNLOAD=true # 开倒排索引用于全文搜索,按官方说法会增加25%的空间,但测试下来并没有暴力搜索快 export ZO_ENABLE_INVERTED_INDEX=true # 快速查询模式默认开启 export ZO_QUICK_MODE_ENABLED=true export ZO_QUICK_MODE_NUM_FIELDS=100 # 内存配置低时建议建议查询器内存,会明显影响查询效率 export ZO_MEMORY_CACHE_MAX_SIZE=128 export ZO_MEMORY_CACHE_DATAFUSION_MAX_SIZE=256 nohup ./openobserve >./logs/o2.log 2>&1 & - nginx 代理
- https://openobserve.ai/docs/operator-guide/nginx_proxy/
- 就是一行proxy_pass,默认ZO_BASE_URI为/web
location /web/ { proxy_pass http://127.0.0.1:5080; }
客户端推送日志
- Filebeat直接使用官方配置即可,登录后可以找到配置
- 由于个人习惯 ,使用了httpout的Filebeat
- https://github.com/fufuok/beats-http-output
- 可以直接使用http压缩流上传
- 注意以下参数
- format:json_lines
- path:/api/default/index/_multi
- 其中index为流名称
- 批量压缩上传的话api要用_multi
- api参考:https://openobserve.ai/docs/api/ingestion/logs/multi/
Telegraf推送监控指标数据
- 就O2来说Telegraf比Prometheus更灵活
- 参考
web
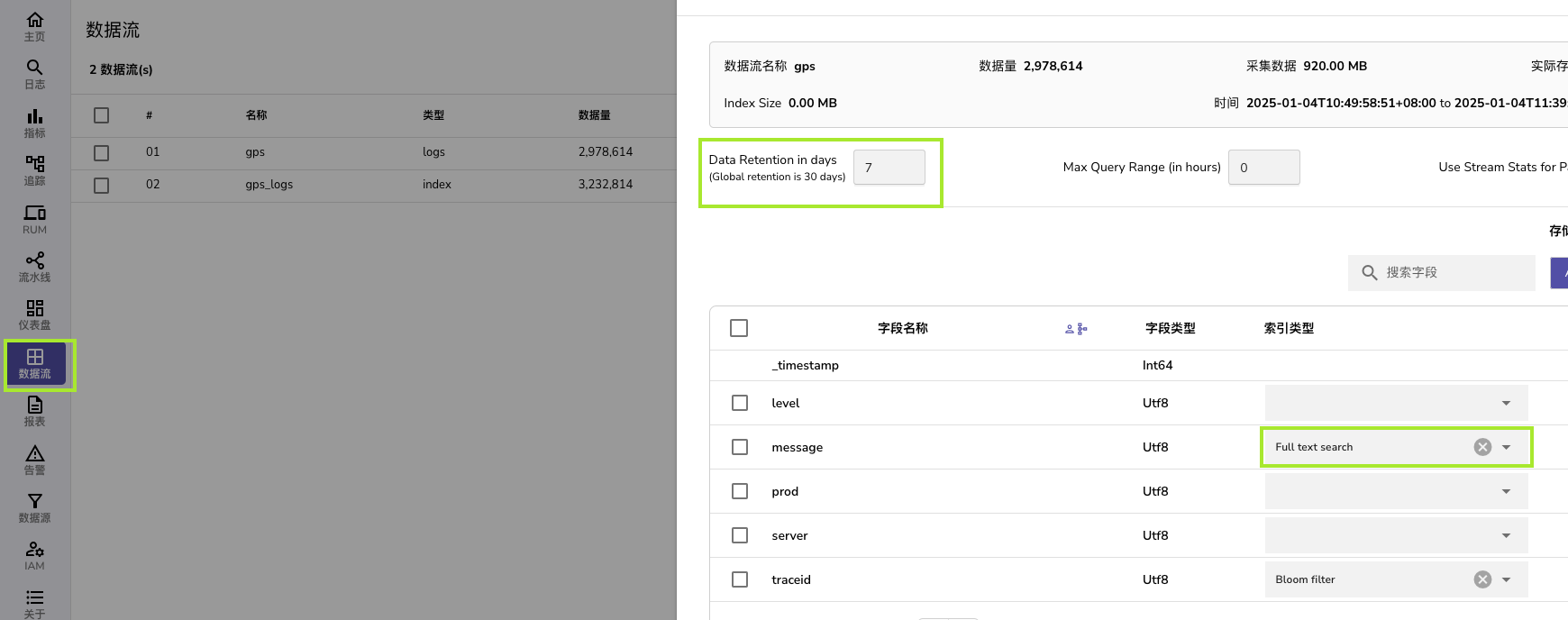
web数据流配置及日志查询
- 客户端推上去之后,web端就可以看到数据流,可以配置全文搜索是哪一列及数据保存时间
- 这里我配置了数据保存时间为7天,全文搜索列为message,同时给traceid配置了布隆过滤
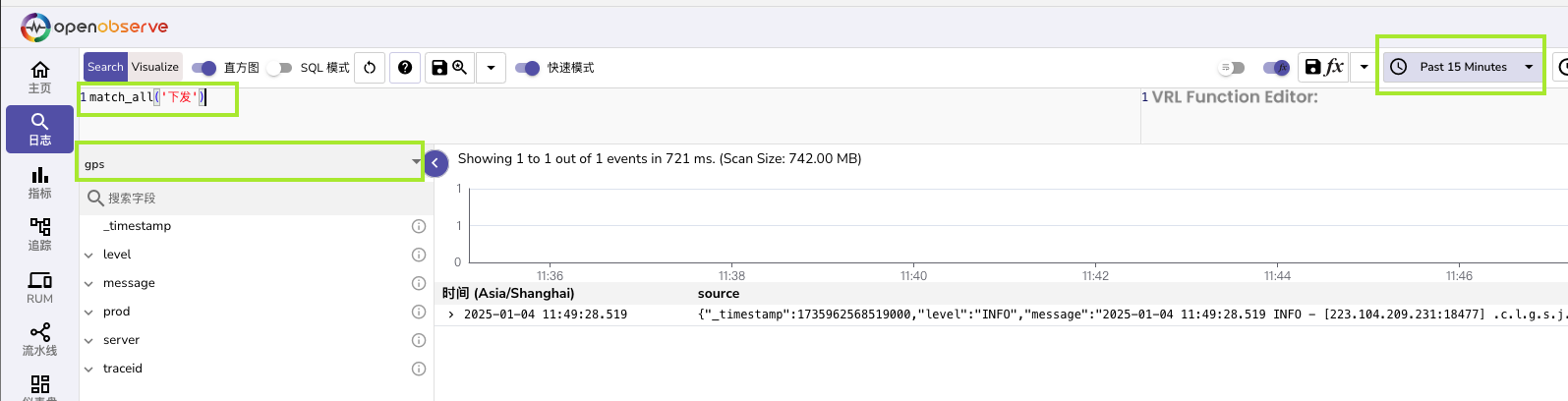
- 日志搜索基本和Kibana差不多,至少长的差不多,日志一般可以无脑match_all
- 注意选 数据流和右上角时间,一般建议时间跨度不过天
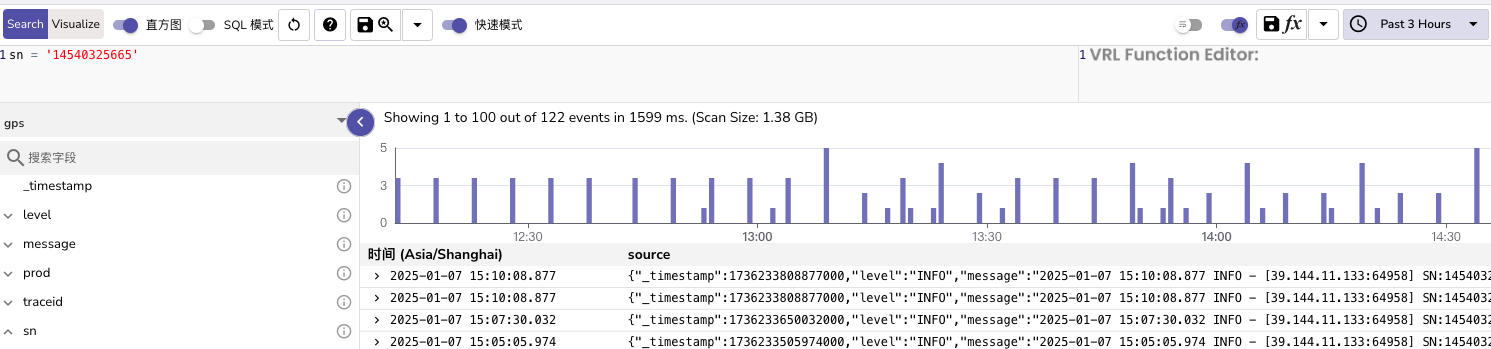
- 搜索效率方面
- 倒排索引对match_all提升不大,并且生成的索引文件和日志文件差不多大
- bloom过滤可用于serverId类字段,但提升不明显,同样会生成索引文件
- 建议使用分区键,并使用 = 做搜索,可明显提升搜索性能
- 对于serverId类字段使用prefix parttion
- 对于traceId/userId/derviceId类字段使用 hash partion(8/16/32)
- 测试1小时400万日志,3.5万tracdId,使用hash parttion(8)分区,按traceid查3小时内数据基本可以秒出(1.5秒左右),match_all内需要25秒左右
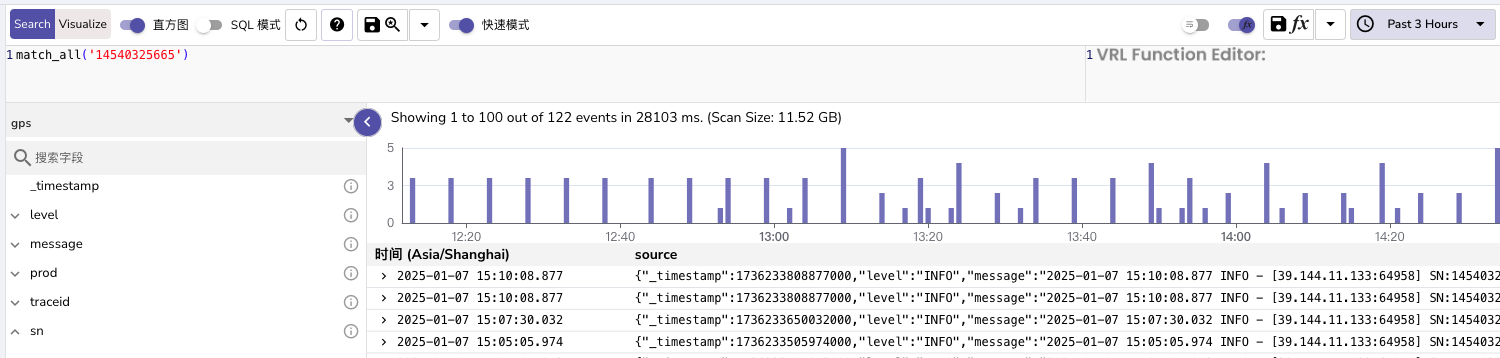
- 其他指标/统计图的,我也不会,理论上也可以做
总结
- 小坑:
- 结束过程后,需等文件同步完再启动,直接启动会报错
- 如果机器内存低于2G,建议加点swap,避免内存不足当机
- o2释放内存非常快,基本影响不大
- vs clickhose
- o2吃内存较多,流量小的情况下基本不怎么吃cpu
- 缺点:
- 默认单机方案sqlite性能不太好
- 可切到mysql,切到mysql+s3(oss) 可简单的组查写分离
ZO_META_STORE: "mysql" ZO_META_MYSQL_DSN: "mysql://user:12345678@localhost:3306/openobserve" - s3 可以考虑aws/阿里云/腾讯云,也可以考虑自布seaweedfs/RustFS/旧版本miniIo
- 低配置机器下,也会会莫名其妙的挂掉,建议配置守护机制使用
- 默认单机方案sqlite性能不太好
- 优点:
- 可控性比clickhose强,底配机器不会持续高位占用CPU
- 相对clickhose简单,不需要自己研究索引
- 自带web界面
- 全文搜索速度可以
- 机器性能不高的情况下建议杜绝无参查询
- 查询效率大致如下
- 10分钟内数据 400ms
- 30分钟内数据 1300ms
- 1小时内数据 3000ms
- 他会分两次查询,第一次只查询第一页,二次查询全部,肉眼上大概在100ms
- 默认带缓存,已查询过的数据数据下次查询很快
- 压缩率比clickhose要好
- o2压缩率有10%,压缩算法是zstd,没有其他压缩选项
- 用s3的话实际存储的数据会比统计数据多40%,算下来压缩率15的样子
- o2会根据查询自动生成index,数据量和存储量差不多,加上的话压缩率就有25%,不过这个index随时可以删
- clickhose压缩率大概50的样子(可能是我配置有问题)
- 上图是o2,下图是CK
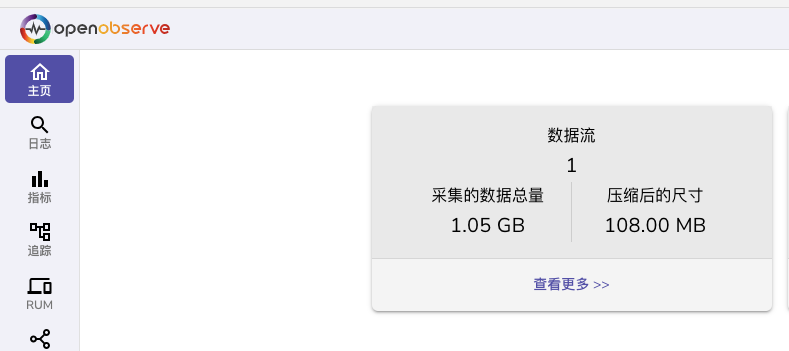
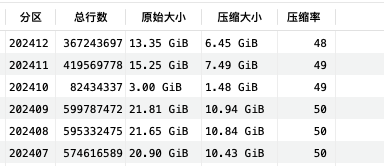
- o2压缩率有10%,压缩算法是zstd,没有其他压缩选项